The Safest Way to Use AI With School Data: Don't Show It the Data
I’ve spent the past year trying to get AI to do useful things with school data. Attendance patterns, behaviour trends, attainment gaps, the kind of analysis that school leaders need but rarely have time to do properly. The promise is compelling: ask a question in plain English, get an answer drawn from your MIS data. No spreadsheets, no pivot tables, no waiting for someone in the office to run a report.
The reality has been more complicated. I’ve tried two fundamentally different approaches, and they produce very different results. One works reliably. The other is a trap.
Two ways to give AI access to school data
The obvious approach is to give the AI the data itself. Export a spreadsheet of Year 8 attendance records, paste it into a prompt, and ask your question. Or load pupil data into a vector store so the AI can search through it. This feels intuitive. The AI has the information, so it should be able to answer questions about it.
The less obvious approach is to give the AI the structure of the data, not the data itself. Tell it what tables exist, what columns they contain, what the data types are. Then ask your question. The AI generates a database query (SQL, an API call, whatever the system supports) that runs against the school’s own database. The AI never sees a single pupil record.
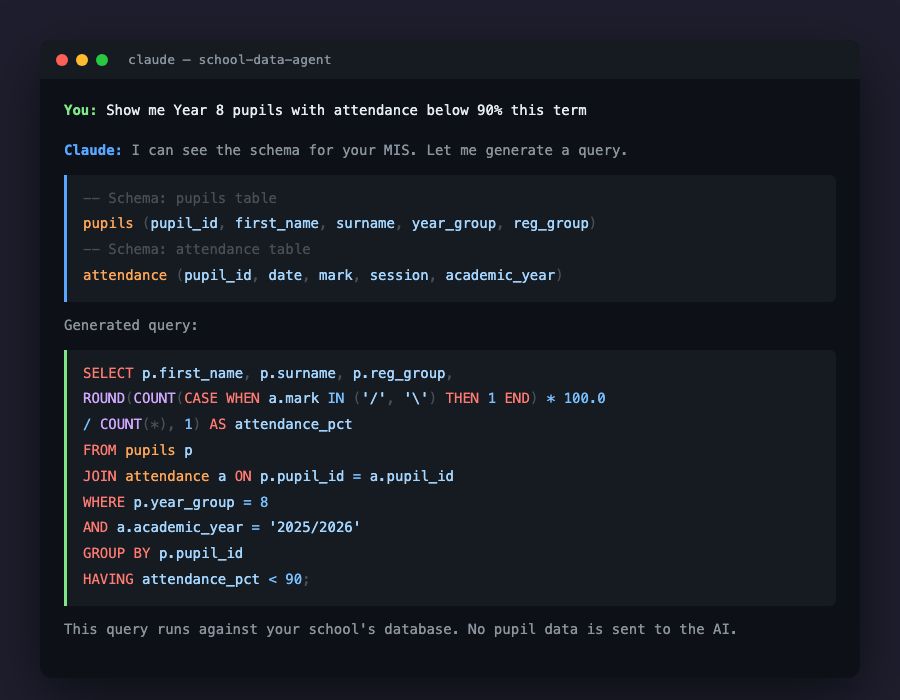
To make this concrete: imagine asking “Show me Year 8 pupils with attendance below 90% this term.” With the first approach, you’d paste hundreds of attendance records into the AI and hope it counts correctly. With the second, the AI reads the schema, understands that there’s a pupils table with a year_group column and an attendance table with mark and date columns, and writes a query that pulls exactly the right data. The query runs locally. The results come back from the school’s own database, not from the AI.
Why the raw data approach breaks down
Feeding actual pupil data into an AI works for small examples. Ask it to summarise ten rows of attendance data and you’ll get a reasonable answer. But school datasets aren’t ten rows. A secondary school with 1,200 pupils generates thousands of attendance marks per week. Behaviour logs, assessment scores, and demographic data add up fast.
When you load this volume of data into an AI prompt or a vector store, several things go wrong. The AI starts hallucinating statistics, confidently reporting percentages that don’t match the underlying data. Ask the same question twice and you might get different answers. Vector stores chunk the data in ways that lose context: a pupil’s attendance figure ends up separated from their name and year group, so the AI pieces together fragments without the full picture.
The structure-based approach avoids all of this. The AI generates a deterministic query. Run it once, run it a hundred times, you get the same result. The database does what databases are designed to do: store, filter, and aggregate data accurately. The AI does what it’s good at: understanding natural language and translating it into a structured request.
Keeping pupil data where it belongs
The accuracy argument might be enough on its own, but there’s a more fundamental problem with feeding school data into AI systems. Schools hold some of the most sensitive personal data anywhere. Pupil names, dates of birth, SEN status, safeguarding flags, free school meal eligibility, medical conditions, family circumstances. This is special category data under UK GDPR, and it demands the highest level of protection.
Pasting pupil records into an AI prompt, even a private one, raises serious questions. Where is that data processed? Is it stored? Who has access to the model’s training pipeline? The DfE’s guidance on generative AI in education is clear that schools must protect personal data when using AI tools, and the ICO has made children’s data a regulatory priority. Schools need to be able to demonstrate that personal data isn’t being shared with third-party AI systems unnecessarily.
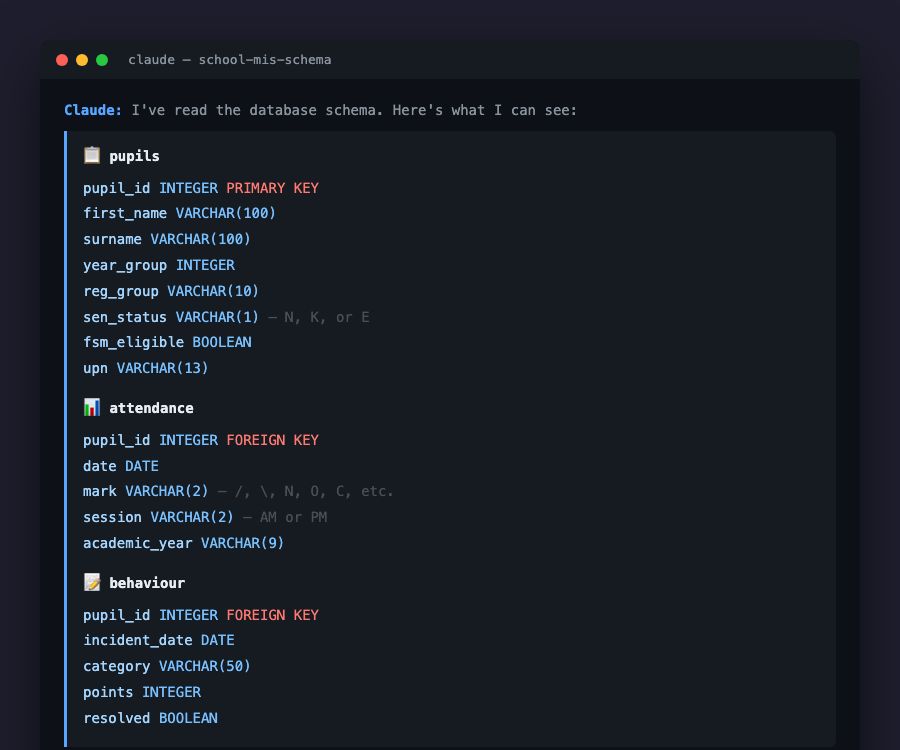
The structure-based approach sidesteps this entirely. The AI sees table names, column names, and data types. It knows that a pupils table has a sen_status column of type VARCHAR(1), but it never sees which pupils have SEN, or their names, or anything else that identifies an individual. The query runs against the school’s own database, within the school’s own infrastructure. The results stay under the school’s control.
This matters for compliance, but it also matters for trust. Schools answering to parents, governors, and Ofsted about their use of AI can point to a clear boundary: the AI understands our data’s shape, but it never touches the data itself.
How this works in practice
The workflow is simpler than it sounds. A school connects their MIS, whether that’s SIMS, Arbor, or another system. The AI reads the database schema or API structure: what tables exist, what fields they contain, how they relate to each other. It builds an understanding of the data’s shape without accessing any records.
A user (a head teacher, a pastoral lead, a school business manager) asks a question in plain English. “Which Year 10 pupils have had more than three behaviour incidents this half-term?” or “What’s the average attendance for pupils eligible for free school meals compared to those who aren’t?” The AI translates that question into a query. The query runs against the school’s database. Results come back.
If needed, the AI can then summarise or visualise those results. But even at that stage, the data stays within the school’s systems. The AI is interpreting results that the school has chosen to share, not rummaging through records on its own.
The key distinction: the AI is a translator, not a data store. It converts human questions into precise database queries. It never needs to hold, process, or transmit pupil-level data.
Where school AI is heading
The current wave of AI tools for schools is still early, and there are platforms already working with trusts to consolidate school data analysis. The ones that will earn long-term trust are the ones that respect the data boundary. Not AI that holds your data, but AI that understands your data’s shape and helps you ask better questions of it.
This is exactly the kind of problem we’re working on at Ask.School. The principle is straightforward: if the AI never sees the sensitive data, there’s nothing to leak, nothing to misprocess, and nothing to explain to the ICO. The hard part is making the experience feel effortless for a head teacher who just wants to know which pupils need attention this week. That’s the engineering challenge, not the data protection one. Get the architecture right and the data protection follows.